What Selection Redesign Actually Looks Like
Two cases from 17 years managing multi-unit retail across Texas. Both with the same pattern: same people, different selection pressure, different outcome.
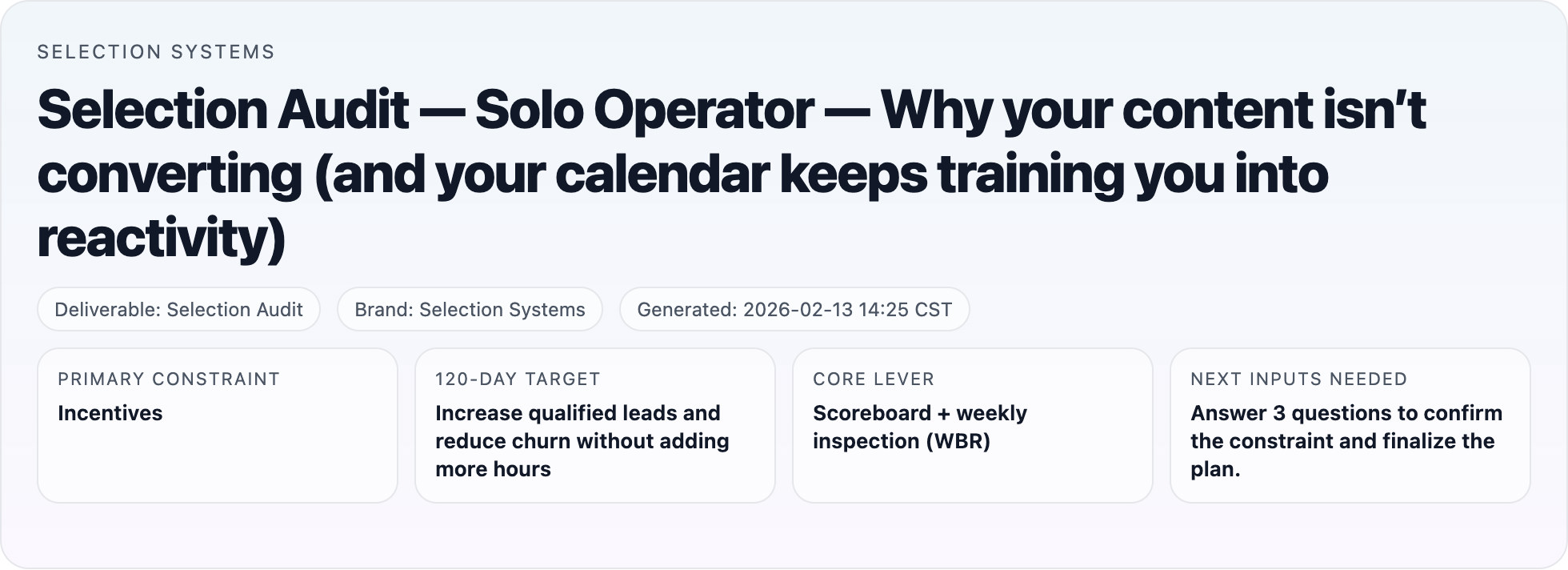
Case 1 — Underperforming location
Arlington Highlands: $100–200/day → $800–1,200/day in six months
6× daily sales
Same staff
Same product mix
6 months
When I took over this location, daily sales were running $100–200. The store had been failing for over a year. Three previous managers had been cycled through. Headcount was the same. Inventory was the same. Layout was the same.
What was different was what the environment was reinforcing. The schedule was built around traffic predictions that were six months stale, so staff were on the floor when no customers were there and missing when traffic peaked. The KPI conversation in huddles centered on transaction count, which the team couldn't directly control — so they tuned it out. Customer complaints went to a paper log nobody read, so service quality drifted with no feedback loop. The environment was selecting for showing up, not for serving customers well.
I didn't motivate the team. I didn't replace anyone. I changed three things: shifted scheduling to match real foot traffic by daypart, switched the daily metric from transactions to attach rate (something staff could move with a single conversation per customer), and made customer feedback a five-minute closing-shift ritual instead of a logbook.
Six months later: $800–1,200 daily. Same people. The system was now selecting for the behavior that produced the outcome.
Case 2 — System-wide adoption
Bannecker Group: 0% → 23.2% loyalty enrollment, 52% above system average
0% → 23.2% adoption
52% above system avg
Multi-unit operator
The franchise system had rolled out a new loyalty program. Corporate had run training, sent communications, set targets. The Bannecker Group's locations were enrolling 0% — flat zero. The other operators in the region were averaging around 15%.
The diagnosis wasn't training. It wasn't culture. It was that the enrollment ask happened at the worst possible moment in the transaction — at the register, when both staff and customer were under time pressure, with no script and no incentive structure. Selection was running against the behavior.
We moved the ask earlier in the interaction (during the recommendation conversation, not at checkout), gave staff a one-line phrasing they could use without thinking, and tied store-level enrollment to a small but visible weekly recognition. We did not change the program. We did not change the people. We changed the conditions under which the ask happened.
Bannecker Group's enrollment climbed to 23.2% — 52% above the system average. The mechanism wasn't motivation. It was making the right behavior easier than the wrong one, and making the result visible enough to reinforce itself.
Both of these are 17-year-old patterns now packaged as the four primitives you learn in the audit: Selection Mapping, Selection Pressure Design, Ruthless Curation, and Self-Directed Evolution.